Summary
Lagopus switchの性能測定を試しにやってみましょう。
まずは単純なフロー(左から入ったら右へ、右から入ったら左へ)を入れて、およそ限界と考えられる性能を確認します。
構成図
こういう感じでひとつお願いします。
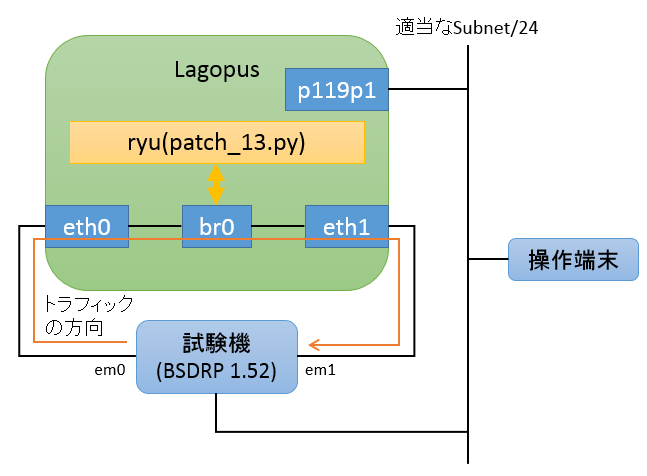
接続している試験ポートは、いずれもIntel EXPI9402PTによるものです。ちょっと古いんだよねぇ。
動作環境
試験機側は 以前作った試験機 と一緒。
あと、Lagopus switchを動作させるPCも、上記のマシンとシステムHDDの容量を除いて同一構成(C2550D4I + 16GMem(SMD-16G28ECP-16KL-D DDR3-1600) + Intel EXPI9402PT)で、
OSはubuntu 14.04.1 amd64を使います。
Lagopusとryuのインストール方法は、いずれも前の記事と同様です。違うのはハードウェア構成くらいです。
コントローラの起動
こんな感じで、初期フローを入れるだけのアプリを書きます。
/tmp/patch_13.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
from ryu.base import app_manager
from ryu.controller import ofp_event
from ryu.controller.handler import CONFIG_DISPATCHER
from ryu.controller.handler import set_ev_cls
from ryu.ofproto import ofproto_v1_3
class Patch13(app_manager.RyuApp):
OFP_VERSIONS = [ofproto_v1_3.OFP_VERSION]
def __init__(self, *args, **kwargs):
super(Patch13, self).__init__(*args, **kwargs)
self.mac_to_port = {}
@set_ev_cls(ofp_event.EventOFPSwitchFeatures, CONFIG_DISPATCHER)
def switch_features_handler(self, ev):
datapath = ev.msg.datapath
parser = datapath.ofproto_parser
match = parser.OFPMatch(in_port=1)
actions = [parser.OFPActionOutput(2)]
self.add_flow(datapath, 0, match, actions)
match = parser.OFPMatch(in_port=2)
actions = [parser.OFPActionOutput(1)]
self.add_flow(datapath, 0, match, actions)
def add_flow(self, datapath, priority, match, actions, buffer_id=None):
ofproto = datapath.ofproto
parser = datapath.ofproto_parser
inst = [parser.OFPInstructionActions(ofproto.OFPIT_APPLY_ACTIONS, actions)]
mod = parser.OFPFlowMod(datapath=datapath,
priority=priority, match=match,
instructions=inst)
datapath.send_msg(mod)
|
で、こんな感じで起動。
1
|
$ ryu-manager --log-file=/tmp/ryu.log /tmp/patch_13.py >/dev/null 2>&1 &
|
ryuの方は、ログを出すようにアプリを書いていないのと、スイッチとの通信は初期フローを入れて終了なので、試験に関して意味のあるログは取れません。
Lagopus switchの起動
横着用
1
2
3
4
5
6
7
8
9
10
|
cd ~/dpdk-1.7.1
export RTE_SDK=`pwd`
export RTE_TARGET="x86_64-native-linuxapp-gcc"
sudo modprobe uio
sudo insmod ${RTE_SDK}/${RTE_TARGET}/kmod/igb_uio.ko
sudo insmod ${RTE_SDK}/${RTE_TARGET}/kmod/rte_kni.ko
sudo ./tools/dpdk_nic_bind.py -b igb_uio 0000:01:00.0
sudo ./tools/dpdk_nic_bind.py -b igb_uio 0000:01:00.1
cd /etc/lagopus
sudo lagopus -l /tmp/lagopus.log -- -c3 -n1 -- -p3
|
Warning
bindするNICは手元の環境に合わせてください。
測定開始
以前作った試験機 を使って、下記のスクリプトを叩き込む。(前回とほぼ同様です)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
#!/bin/sh
show()
{
ssh root@192.168.1.2 lagosh << _EOL_ >> ${EXAM}_pkt-gen_lagopus.log 2>&1
show bridge-domains
show controller 127.0.0.1
show flow
show flowcache
show interface all
_EOL_
sysctl dev.em >> ${EXAM}_sysctl_em.log 2>&1
}
send()
{
show
pkt-gen -i em1 -f rx -w 4 > ${EXAM}_pkt-gen_rx_em1.log 2>&1 &
pkt-gen -i em0 -f tx -w 5 -l ${LENGTH} -S 00:15:17:3a:84:aa -D 00:15:17:3a:84:ab -s ${SRC} -d ${DST} -n ${COUNT} > ${EXAM}_pkt-gen_tx_em0.log 2>&1
sleep 1
kill -INT `ps a | grep '[p]kt-gen -i em1 -f rx' | cut -f 1 -d ' '`
show
sleep 10
}
sysctl dev.em.0.fc=2
EXAM="1-1"; LENGTH="60"; SRC="192.0.2.1"; DST="192.0.2.101"; COUNT=267858000; send
EXAM="1-2"; LENGTH="60"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101"; COUNT=267858000; send
EXAM="1-3"; LENGTH="60"; SRC="192.0.2.1"; DST="192.0.2.101-192.0.2.200"; COUNT=267858000; send
EXAM="1-4"; LENGTH="60"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101-192.0.2.200"; COUNT=267858000; send
EXAM="2-1"; LENGTH="124"; SRC="192.0.2.1"; DST="192.0.2.101"; COUNT=152028000; send
EXAM="2-2"; LENGTH="124"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101"; COUNT=152028000; send
EXAM="2-3"; LENGTH="124"; SRC="192.0.2.1"; DST="192.0.2.101-192.0.2.200"; COUNT=152028000; send
EXAM="2-4"; LENGTH="124"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101-192.0.2.200"; COUNT=152028000; send
EXAM="3-1"; LENGTH="252"; SRC="192.0.2.1"; DST="192.0.2.101"; COUNT=81522000; send
EXAM="3-2"; LENGTH="252"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101"; COUNT=81522000; send
EXAM="3-3"; LENGTH="252"; SRC="192.0.2.1"; DST="192.0.2.101-192.0.2.200"; COUNT=81522000; send
EXAM="3-4"; LENGTH="252"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101-192.0.2.200"; COUNT=81522000; send
EXAM="4-1"; LENGTH="508"; SRC="192.0.2.1"; DST="192.0.2.101"; COUNT=42300000; send
EXAM="4-2"; LENGTH="508"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101"; COUNT=42300000; send
EXAM="4-3"; LENGTH="508"; SRC="192.0.2.1"; DST="192.0.2.101-192.0.2.200"; COUNT=42300000; send
EXAM="4-4"; LENGTH="508"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101-192.0.2.200"; COUNT=42300000; send
EXAM="5-1"; LENGTH="1020"; SRC="192.0.2.1"; DST="192.0.2.101"; COUNT=21564000; send
EXAM="5-2"; LENGTH="1020"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101"; COUNT=21564000; send
EXAM="5-3"; LENGTH="1020"; SRC="192.0.2.1"; DST="192.0.2.101-192.0.2.200"; COUNT=21564000; send
EXAM="5-4"; LENGTH="1020"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101-192.0.2.200"; COUNT=21564000; send
EXAM="6-1"; LENGTH="1276"; SRC="192.0.2.1"; DST="192.0.2.101"; COUNT=17316000; send
EXAM="6-2"; LENGTH="1276"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101"; COUNT=17316000; send
EXAM="6-3"; LENGTH="1276"; SRC="192.0.2.1"; DST="192.0.2.101-192.0.2.200"; COUNT=17316000; send
EXAM="6-4"; LENGTH="1276"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101-192.0.2.200"; COUNT=17316000; send
EXAM="7-1"; LENGTH="1514"; SRC="192.0.2.1"; DST="192.0.2.101"; COUNT=14634000; send
EXAM="7-2"; LENGTH="1514"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101"; COUNT=14634000; send
EXAM="7-3"; LENGTH="1514"; SRC="192.0.2.1"; DST="192.0.2.101-192.0.2.200"; COUNT=14634000; send
EXAM="7-4"; LENGTH="1514"; SRC="192.0.2.1-192.0.2.100"; DST="192.0.2.101-192.0.2.200"; COUNT=14634000; send
|
Note
この時、Lagopus switchが送信するPAUSEフレームを無視するために、各IFでは sysctl dev.em.0.fc=2(デフォルトは3) を叩いておく。
そうしないと送信レートがPAUSEフレームに引きずられて下がってしまうので。
また、Lagopusに付属するlagoshと言うシェルから取得できる情報を試験前後で取得するため、事前に sshkeygen して ssh-copy-id を済ませてある。
測定結果
とりあえず、各フレーム長別の送受信レートを見て行こう。
1. 64 Byte (1フロー/100フロー(src)/100フロー(dst)/10000フロー(src+dst))
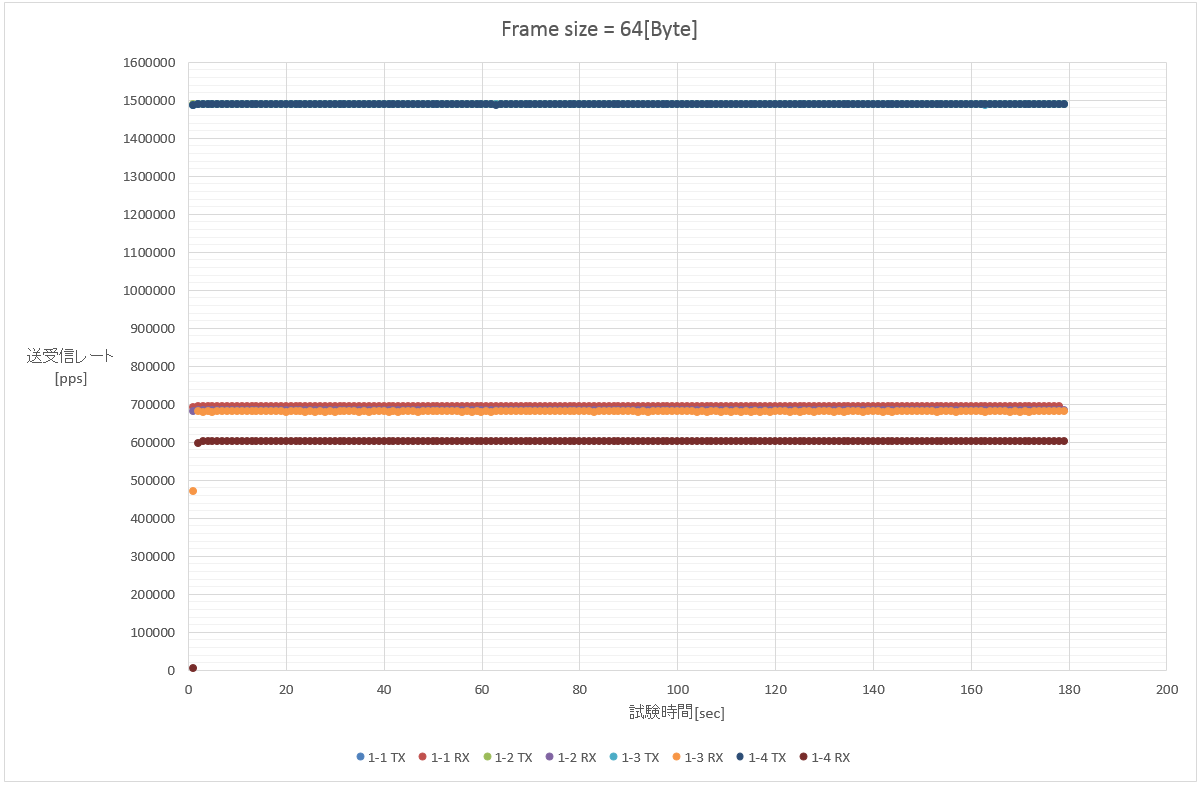
この時点でおおよそLagopusが処理可能な限界パケット転送性能が700[kpps]弱であることが予想される。
また、1-4(10000フロー)の結果が他の試験と比べて若干下がっているため、フロー数が多い環境では性能が下がる可能性があると考えられる。
少し拡大してみよう。
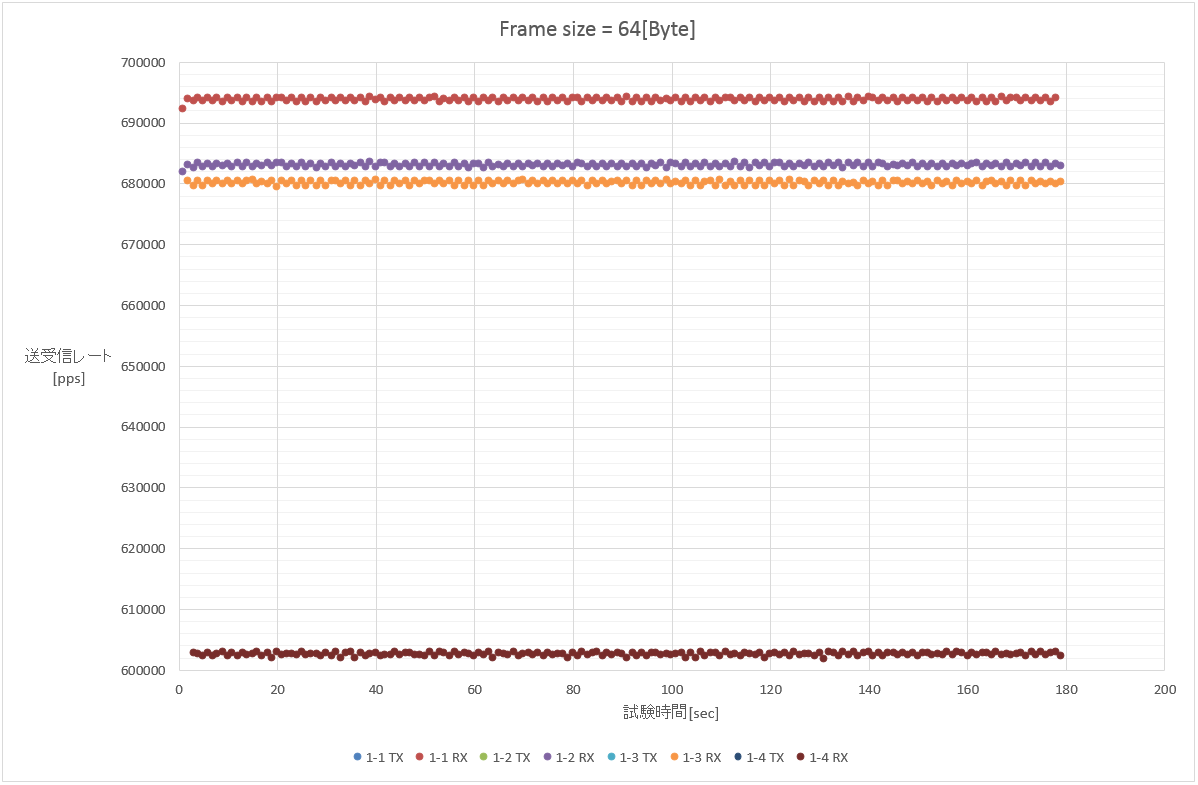
一番上のラインが単一フローの場合で、最も性能が良い。
上から二番目と三番目のラインは送信元を100パターンにばらした場合と宛先を100パターンにばらした場合。
ほぼ同条件と考えられるのだが、宛先をばらしたパターンの方が若干低い数値が出ている。
そして、一番下のラインが送信元と宛先を100パターンずつ掛け合わせた10000フロー。
明確に他の試験パターンと比べて低い数値が出ている。
一般に、現在普及しているLinux等のOSを用いたパケット転送は、帯域幅よりも単位時間あたりに処理するパケット数によってその性能が決まる。
従って、他のフレーム長における試験結果についても、600kppsから700kppsの範囲、もしくはリンク速度限界のいずれかで頭打ちになる。と考えられる。
2. 128 Byte (1フロー/100フロー(src)/100フロー(dst)/10000フロー(src+dst))
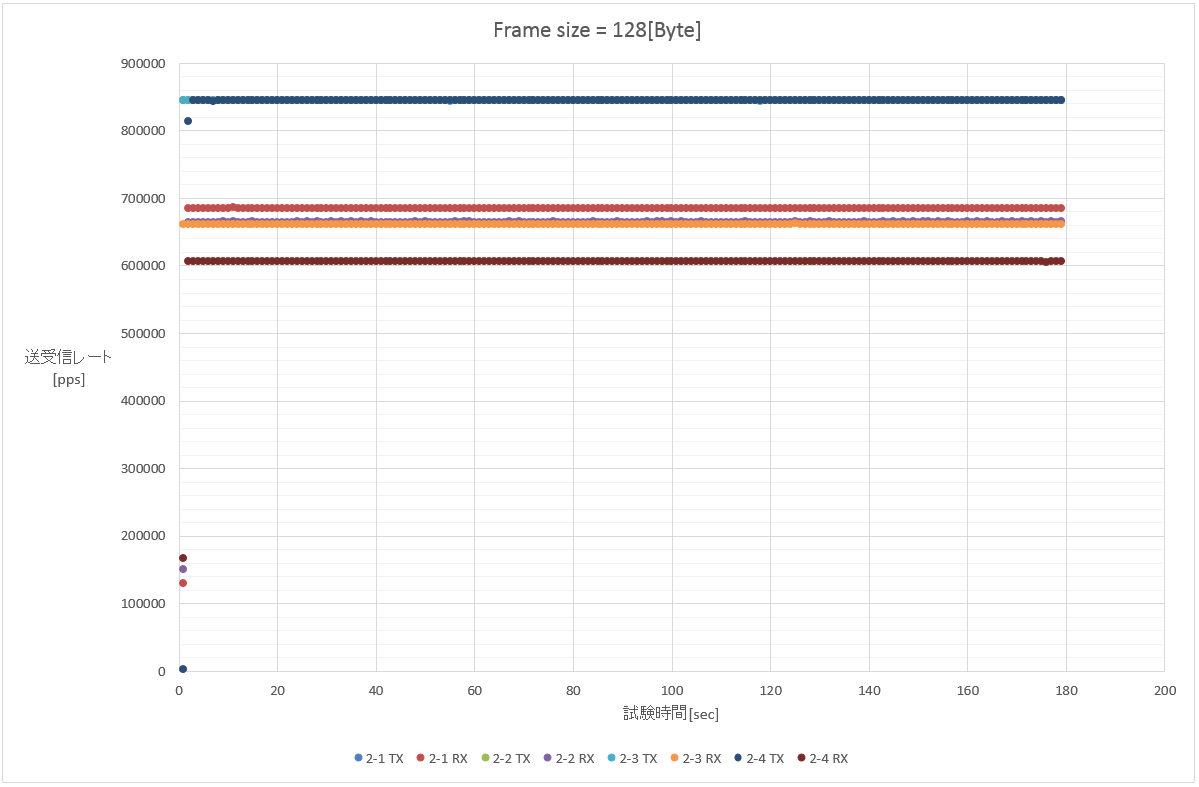
と言うわけで、試験1と同様のパケット転送性能を確認。ノーコメント。
3. 256 Byte (1フロー/100フロー(src)/100フロー(dst)/10000フロー(src+dst))
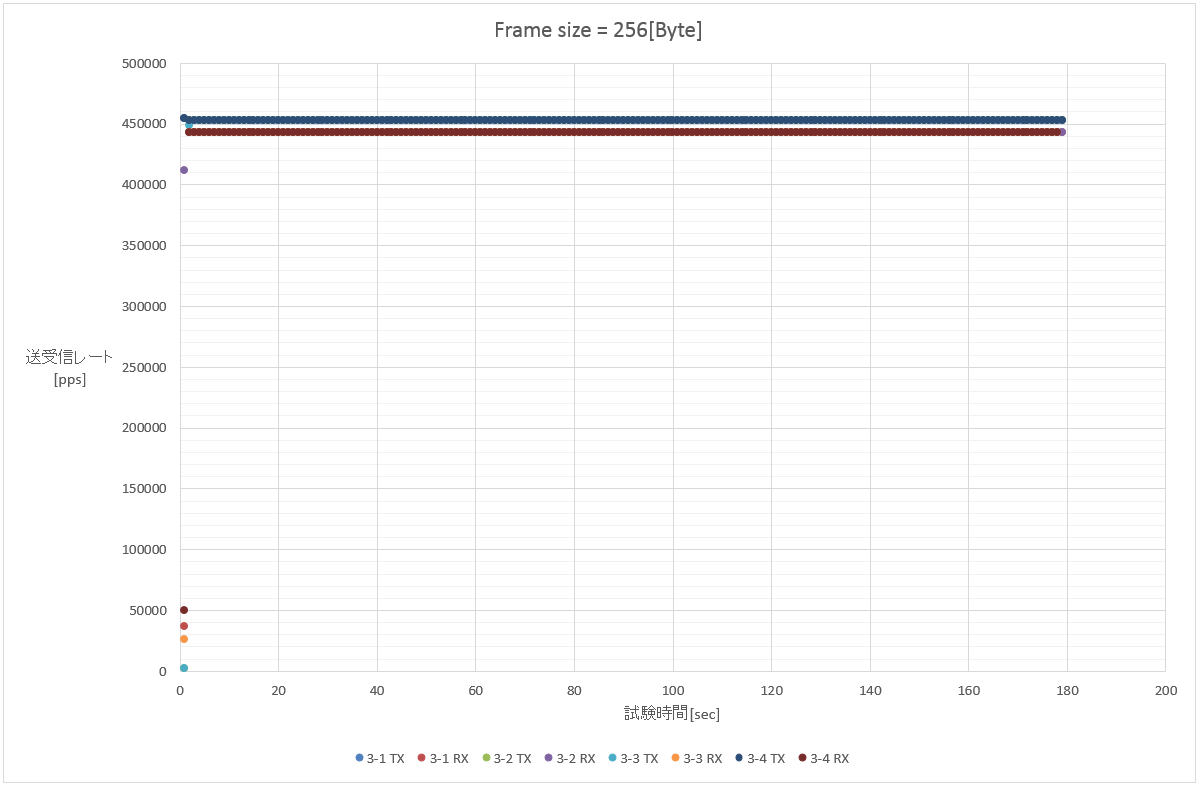
試験3(フレーム長256[Byte]以上の試験)以降は、1Gbpsの理論パケットレートが600kppsを下回るため、おおよそ送受信レートが一致することが期待される。
のだが、微妙に足りていない。スポットで取りこぼすタイミングがあるんじゃないかなぁ。
4. 512 Byte (1フロー/100フロー(src)/100フロー(dst)/10000フロー(src+dst))
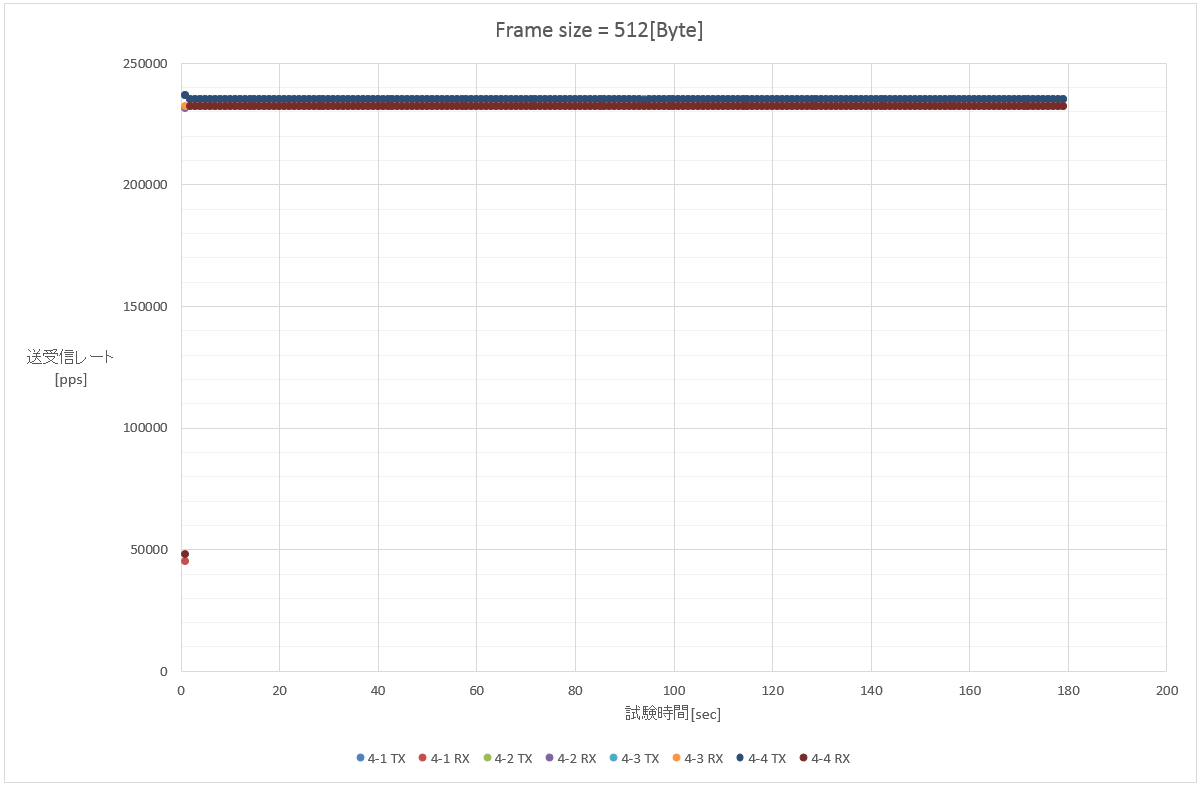
大体一緒。
5. 1024 Byte (1フロー/100フロー(src)/100フロー(dst)/10000フロー(src+dst))
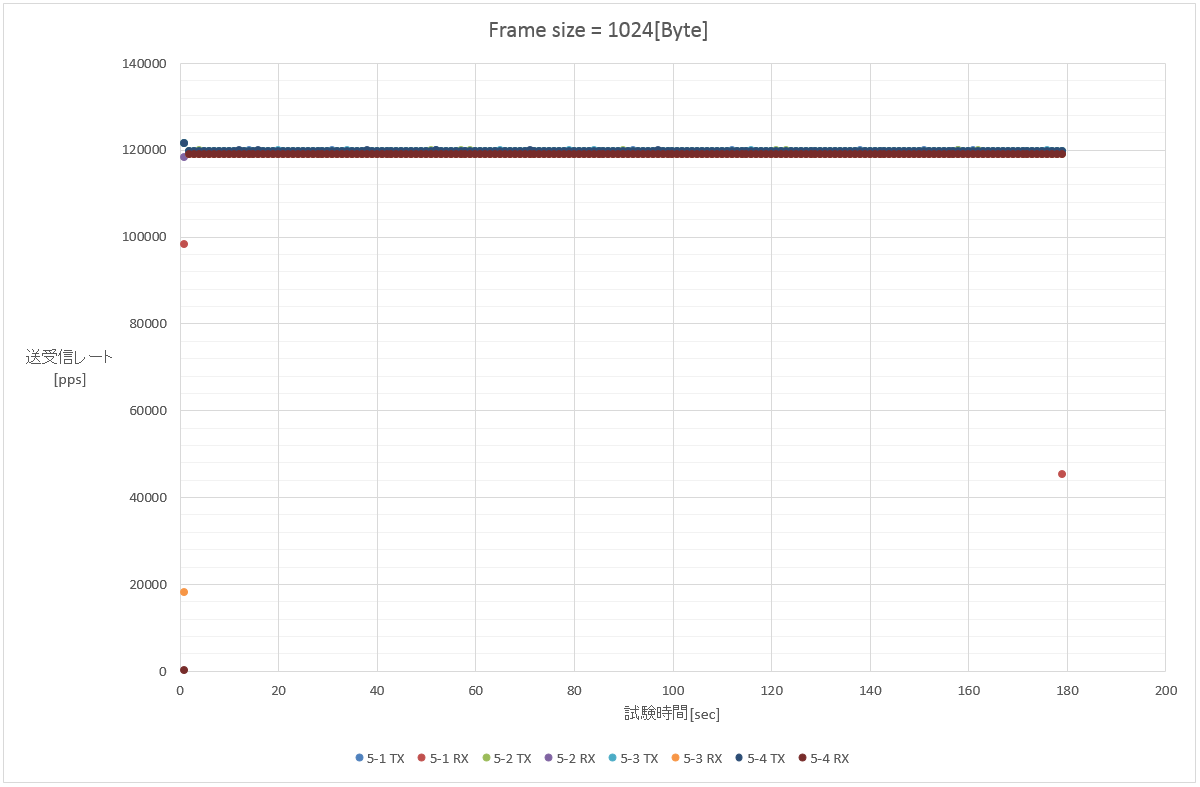
大体一緒。
6. 1280 Byte (1フロー/100フロー(src)/100フロー(dst)/10000フロー(src+dst))
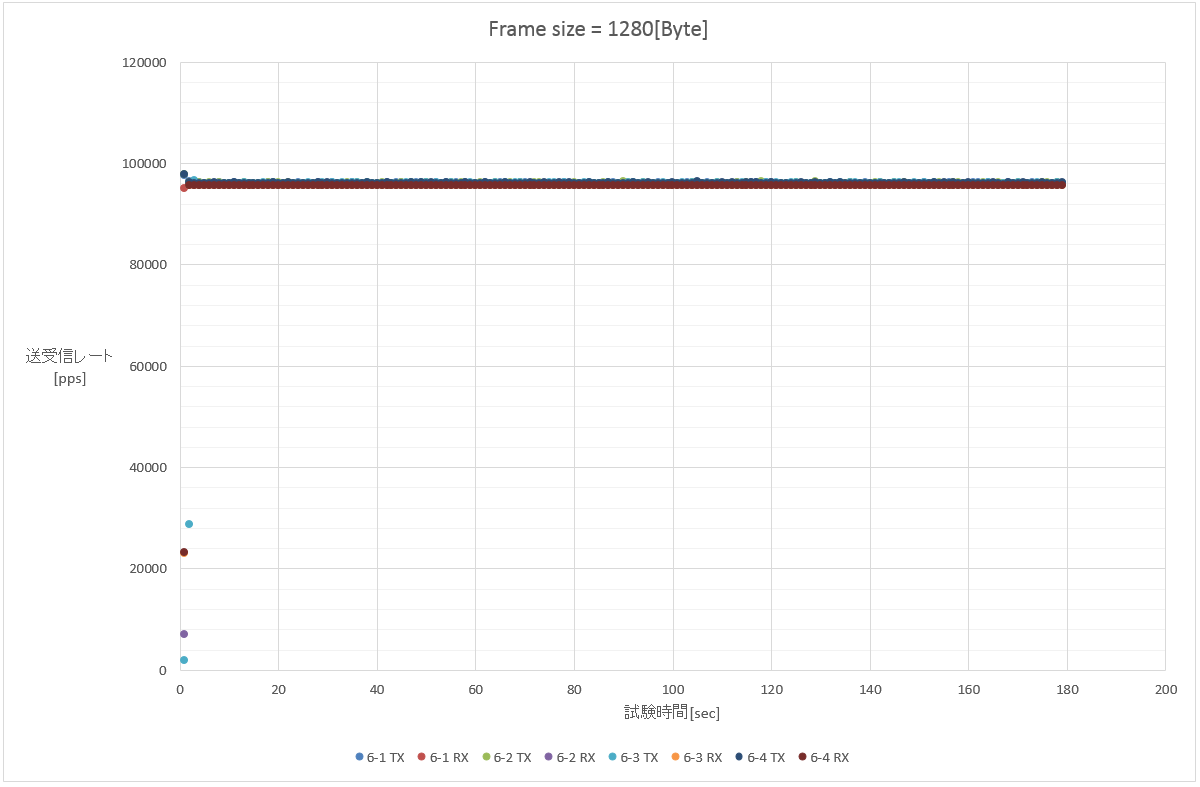
大体一緒。
7. 1518 Byte (1フロー/100フロー(src)/100フロー(dst)/10000フロー(src+dst))
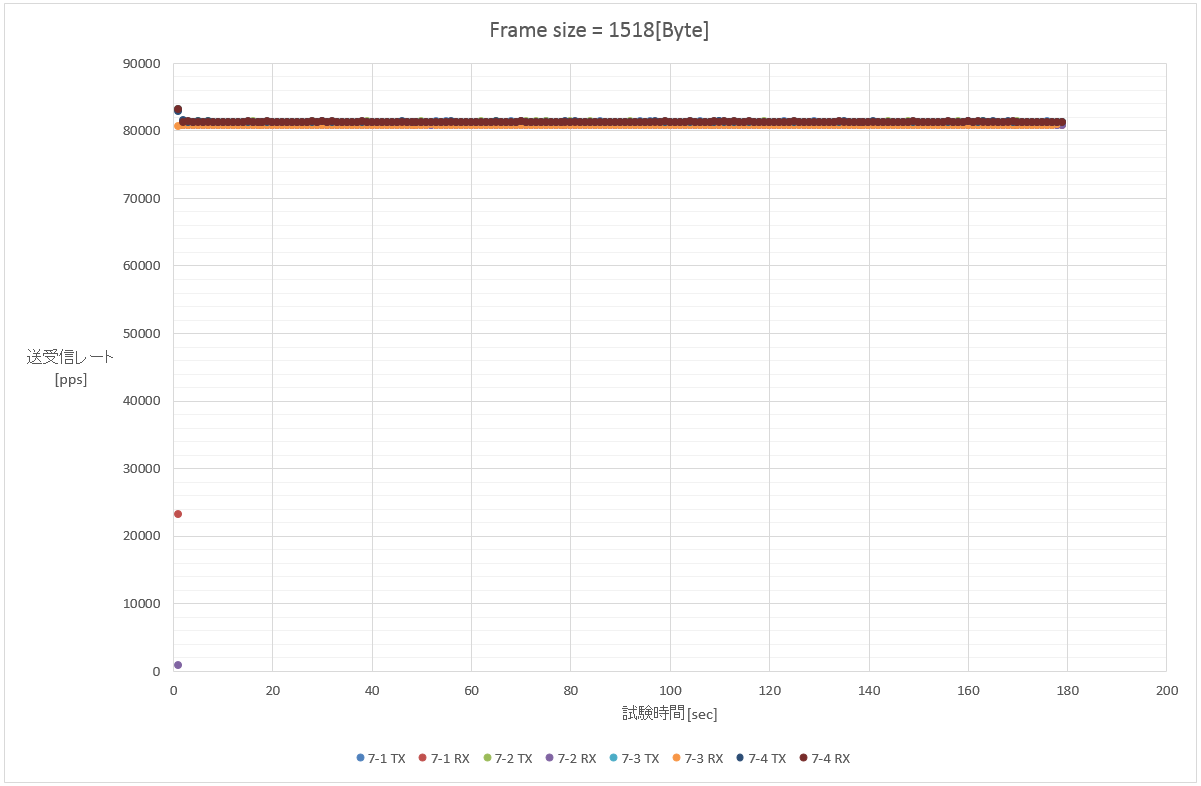
大体一緒。誰も平坦だなんて言ってませんよ。HAHAHA。
送受信カウンタサマリ
まとめるとこんな感じ。
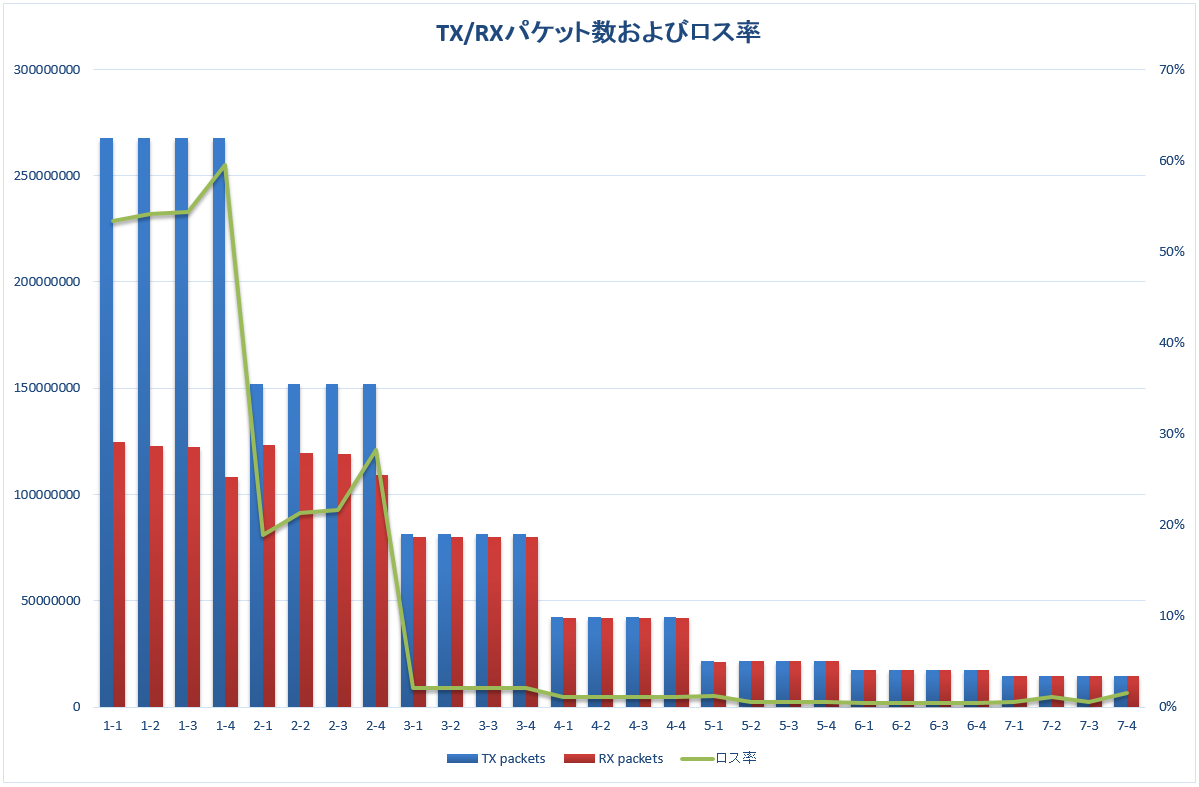
ロス率がゼロにならないところが悩ましい。
フローカウンタ
では、ここでLagopus上で認識しているフローテーブルについても確認する。
今回は、試験の前後で以下のようなログを取得している。
1
2
3
4
5
6
|
$ sudo lagosh
lagopus> show flow
Bridge: br0
Table id: 0
priority=0,idle_timeout=0,hard_timeout=0,flags=0,cookie=0,packet_count=124875085,byte_count=7492505100,in_port=1 actions=output:2
priority=0,idle_timeout=0,hard_timeout=0,flags=0,cookie=0,packet_count=0,byte_count=0,in_port=2 actions=output:1
|
ここから、処理対象となったパケット数を確認できるので、pkt-genの送受信カウンタと合わせて簡単にまとめる。
| Exam number |
TX packet count |
RX packet count |
Flow packet count |
TXとの差分 |
RXとの差分 |
| 1-1 |
267858000 |
124875085 |
124875085 |
142982915 |
0 |
| 1-2 |
267858000 |
122932617 |
122932617 |
144925383 |
0 |
| 1-3 |
267858000 |
122404375 |
122404375 |
145453625 |
0 |
| 1-4 |
267858000 |
108444111 |
108444111 |
159413889 |
0 |
| 2-1 |
152028000 |
123323220 |
123323220 |
28704780 |
0 |
| 2-2 |
152028000 |
119665585 |
119665585 |
32362415 |
0 |
| 2-3 |
152028000 |
119100170 |
119100170 |
32927830 |
0 |
| 2-4 |
152028000 |
109159603 |
109159603 |
42868397 |
0 |
| 3-1 |
81522000 |
79785772 |
81522000 |
0 |
-1736228 |
| 3-2 |
81522000 |
79785866 |
81522000 |
0 |
-1736134 |
| 3-3 |
81522000 |
79785830 |
81522000 |
0 |
-1736170 |
| 3-4 |
81522000 |
79785910 |
81522000 |
0 |
-1736090 |
| 4-1 |
42300000 |
41827747 |
42300000 |
0 |
-472253 |
| 4-2 |
42300000 |
41827713 |
42300000 |
0 |
-472287 |
| 4-3 |
42300000 |
41827701 |
42300000 |
0 |
-472299 |
| 4-4 |
42300000 |
41827783 |
42300000 |
0 |
-472217 |
| 5-1 |
21564000 |
21299615 |
21564000 |
0 |
-264385 |
| 5-2 |
21564000 |
21440798 |
21564000 |
0 |
-123202 |
| 5-3 |
21564000 |
21440797 |
21564000 |
0 |
-123203 |
| 5-4 |
21564000 |
21440914 |
21564000 |
0 |
-123086 |
| 6-1 |
17316000 |
17236679 |
17316000 |
0 |
-79321 |
| 6-2 |
17316000 |
17236639 |
17316000 |
0 |
-79361 |
| 6-3 |
17316000 |
17236623 |
17316000 |
0 |
-79377 |
| 6-4 |
17316000 |
17236659 |
17316000 |
0 |
-79341 |
| 7-1 |
14634000 |
14558689 |
14634000 |
0 |
-75311 |
| 7-2 |
14634000 |
14477110 |
14634000 |
0 |
-156890 |
| 7-3 |
14634000 |
14558685 |
14634000 |
0 |
-75315 |
| 7-4 |
14634000 |
14404836 |
14634000 |
0 |
-229164 |
試験2までは、受信数とフローマッチ数が一致する。
つまり、フローマッチしたパケットはそのまま転送されており、転送できなかったパケットはフローマッチ前に捨てられたと考えられ、パケット処理性能の限界値から見ると妥当な結果と考えられる。
続いて、パケット処理性能の限界値からすると、おそらくこの辺はワイヤレートで転送出来ていてもいいんじゃないかな、と言う試験3以降。
こちらは興味深いことに、フローマッチ後にパケットロスが発生している。
back-to-backで接続していた時には、試験機の受信側は特に問題なかったので、DPDKの周辺設定によるものだろうか。
ただ、間に何か挟むとpkt-gen側が取りこぼす可能性も無いではないので、OVS辺りと比較してから考えてみようか。
もし、無チューニングでは高レート環境でパケットロスが多発する問題を抱えているのだとしたら、より詳細に調査する必要があるかもしれない。
ping6による遅延測定
測定と言う程きっちりしたものではないが、ping6によるRTTの測定もしておこう。
IPv4を使うと同じサブネットだの何だので簡単に試験がやりにくいので、ping6をリンクローカルで使うことでさっくりテストする。
一応、back-to-backとLagopusを挟んだ場合の2パターンを取得。
コマンド
1
|
# ping6 -i 0.01 -c 18000 fe80::215:17ff:fe3a:84ab%em0 > ping6.log
|
遅延グラフはこんな感じ。
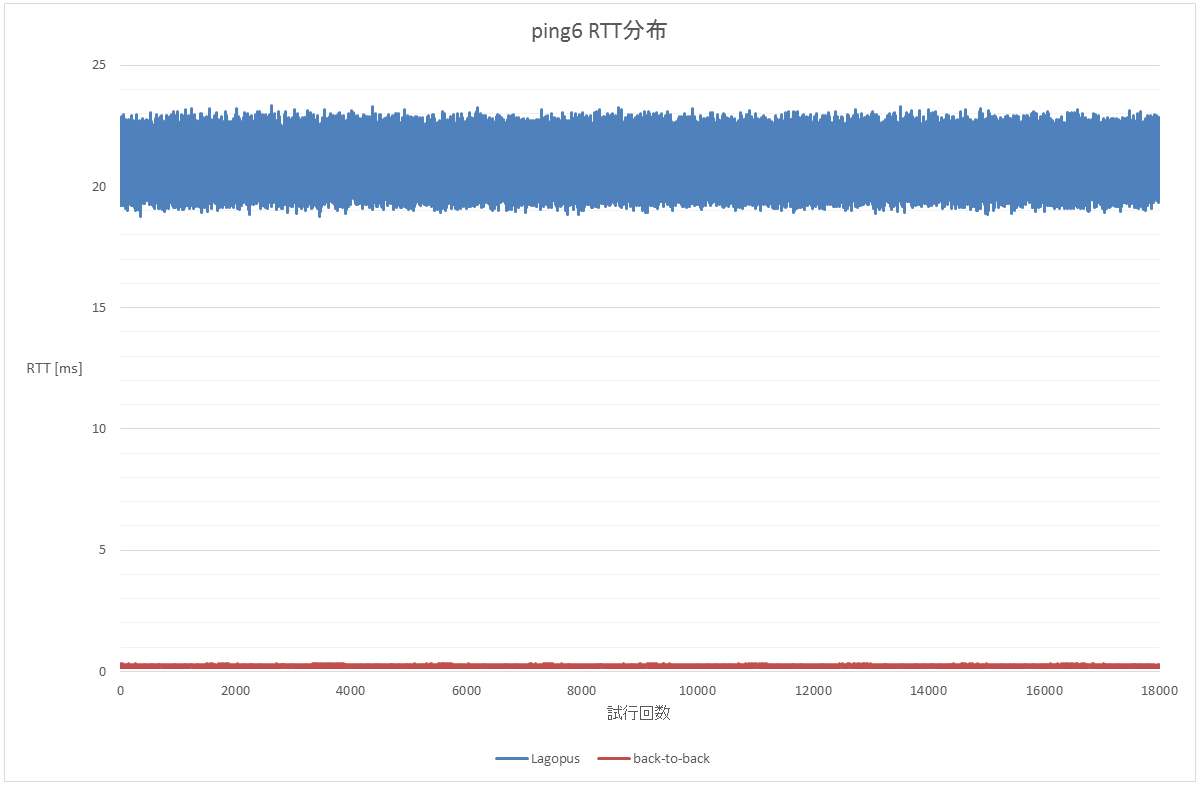
back-to-backで 0.2[msec] とかなのに、Lagopus挟んだだけで 20[msec] 前後になるってのは…どう考えてるんだろう。
一応、IntelはProgrammer’s guide - DPDKの37.3.1 Lower Packet Latencyでバーストサイズを小さくしろって言ってるんだけど、Lagopusはどうなってるのかね。
まぁそっちは余裕があれば見に行きましょう。
おしまい
とりあえずのお試し試験だったけど、今回いくつかの課題が確認できた。
- トラフィックが複数フローになると性能が低下しそう
- 微妙にパケットロスする
- とっても遅延ありそう
今回は片方向にしかトラフィックを流していないので、単純に双方向にした場合の結果も確認しないといけない。
Open vSwitchとの対比も、できたらいいなぁ。
多数のフローエントリを登録した場合の性能についても確認する必要もあるし、トポロジをもう少し複雑にしないと実際的じゃない(ただ、今のところ機材が無い)。
ただまぁ、その、暇があればね!