サマリー
Proxmox VE cluster再構築と移行の雑記 で構築したProxmox VEクラスタのCephベンチマークを取ったので、結果を整理しておきたいと思います。
ベンチマーク構成
| 項目 | 旧クラスタ | 新クラスタ |
|---|---|---|
| ベースHW | TX1320 M2 x 3 | ThinkCentre M75s Gen5 x 3 |
| OS | Proxmox VE 8.3 | Proxmox VE 8.3 |
| CPU | Xeon E3-1220v5/Xeon E3-1230v5(混在) | Ryzen 7 Pro 8700G (APU) 8C/16T |
| Memory | DDR4-2133 ECC 64GB/32GB(混在) | DDR5-5600 ECC 32GB x2(64GB) |
| Ceph version | 19.2.1 | 19.2.1 |
| Ceph OSD | Crucial MX500 2TB | Intel DC S4500 3.84TB |
- 旧クラスタの場合、Ceph NetworkはVMと共用の1G SW(2port bond)に収容されているMTU=9000です
- 新クラスタの場合、Ceph Networkは専用の10G SW(1port)に収容されておりMTU=9000です
- fioを実行するのは同クラスタ内のホストからになります
- 負荷印加システムと負荷対象システムが同一システム上にあるため、純粋なCephの測定結果ではありません
- Hyper-Converged構成なので同一システム上からのfioはqemuからのRBDアクセスと読み替えれば参考にはなるはず
- 10GbEの負荷印加用ノードまでは準備できませんでした
Diskカタログスペック比較
| Crucial MX500 | Intel DC S4500 | |
|---|---|---|
| 型番 | CT2000MX500SSD1 | SSDSC2KB038T7 |
| 発売日 | 2018年1月 | 2017年9月 |
| インターフェース | SATA (6Gb/s) | SATA (6Gb/s) |
| フォームファクター | 2.5inch | 2.5inch |
| 厚さ | 7mm | 7mm |
| 容量 | 2000 GB | 3840 GB |
| 耐久性 | 700 TBW | 7640 TBW |
| Sequential Read | 560 MB/s | 560 MB/s |
| Sequential Write | 510 MB/s | 480 MB/s |
| Random Read I/O | 95,000 IOPS | 72,000K IOPS |
| Random Write I/O | 90,000 IOPS | 33,000K IOPS |
| Read latency (sequential) | 36 µs | |
| Write latency (sequential) | 37 µs | |
| Read latency (random) | 103 µs | |
| Write latency (random) | 59 µs |
耐久性はDWPDからおおよその数値に変換したもの。大して意味はない。
ベンチマーク項目
- Write Cache性能影響
- 今回導入したSATA SSDは https://yourcmc.ru/wiki/Ceph_performance に書かれているWrite Cacheを無効化した方が良いデバイスに相当する可能性があるので、Write Cacheの有無での性能差を見ておきたい
- RBD並列数による性能(n=1)
- RBD並列数による性能(n=2,4,8)
- MX500とS4500の性能差
ベンチマークでは、仮想マシンを必要数分作成し、電源OFFの状態のままにしておきます。
準備が出来たらfioのiniファイルを指定してベンチマークを開始します。
KRBDの測定をする場合はHDDの中身を空っぽにしてBoot画面で止まる仮想マシンにするなど、Diskに影響しない環境を作る必要があります。
1. Write Cache性能影響
SSD Cacheの有効無効はhdparmコマンドで指定します。
無効にするとき
|
|
有効にするときは hdparm -W 1 /dev/sda です。
使用したfioファイルは以下のものです。
fio ceph_bench.ini で実行します。
|
|
ベンチマークに使用するfioの設定ファイルでは、作成済みの仮想マシンが持っている仮想Diskの名前を rbdname に指定して測定します。
Proxmox VEの構成するCephクラスタはアクセスにkeyringが必要になります。
fioでは ioengine=rbd の場合 clientname=admin を設定しておけばceph clientの設定を使ってくれるので、あまり複雑な設定は必要ありません。
参考: https://forum.proxmox.com/threads/fio-with-ioengine-rbd-doesnt-work-with-proxmoxs-ceph.64736/
結果
Sequential Write 4MB iodepth=16
若干WriteCache無効の方が良いかなという程度。
| 項目 | IOPS - ave | BW (MB/s) - ave | Latency (msec) - min | Latency (msec) - max | Latency (msec) - ave |
|---|---|---|---|---|---|
| WriteCache無効 | 103 | 435 | 27 | 232 | 154.19 |
| WriteCache有効 | 100 | 423 | 24 | 386 | 158.71 |
性能公称値であるSequential Write 480 MB/sには若干届いていませんでした。ちょっとiodepth浅かったかな?
Random Write 4KB iodepth=1
若干WriteCache無効の方が良いかなという程度。Latencyの最大値は無効の場合に少し大きいものの、平均で見ると無効の方が良い。
| 項目 | IOPS - ave | BW (MB/s) - ave | Latency (msec) - min | Latency (msec) - max | Latency (msec) - ave |
|---|---|---|---|---|---|
| WriteCache無効 | 1391 | 5.698 | 0.537 | 15.88 | 0.71824 |
| WriteCache有効 | 1165 | 4.775 | 0.641 | 9.092 | 0.85719 |
iodepth=1なので、IOPSがこの程度なのは概ね予想通り。
SSDのWrite latency (random) の公称値が59 µsでも、それ以外の処理時間が上乗せされるのは仕方ありません。
これを劇的に改善するのはCephの仕組み的に難しく、エンタープライズ製品を頑張ってチューニングして3000 IOPSに到達するかどうかだと思います。
参考: Ceph performance: benchmark and optimization | croit
Cephは並列数を上げると性能がスケールするけれども、1jobに対してはかなり低いIOPSになります。
この1job性能をどの程度維持して並列数を上げられるかが気になるところです。
Random Write 4KB iodepth=128
若干WriteCache無効の方が良いかなという程度。
Latencyの最大値は無効の場合に倍に跳ねているものの、平均で見ると無効の方が良い。
負荷印加と測定対象が同じシステム上にあるので、多少外れ値が生まれるのは諦めてください。
| 項目 | IOPS - ave | BW (MB/s) - ave | Latency (msec) - min | Latency (msec) - max | Latency (msec) - ave |
|---|---|---|---|---|---|
| WriteCache無効 | 33096 | 135 | 1.372 | 80.559 | 3.875 |
| WriteCache有効 | 28700 | 117 | 1.229 | 40.489 | 4.46158 |
結論
ひとまずWriteCache無効の方が若干良さそう。
S4500はあまりWriteCacheの影響を強く意識しなくても、それなりに使えてしまうSSDなのかもしれない。
まぁ8年も前のSATA SSDなので、僕が今さら何か言うのもおこがましいよね。
起動時にWriteCacheを無効にする設定
なお再起動すると hdparm -W 0 /dev/sda の設定は消えてしまうので、起動時に設定されるようにudev ruleを書いておきます。
このやり方はCeph公式というよりはArchの方をベースにしています。
|
|
udevadm test /dev/sda コマンドを叩いて run: '/usr/sbin/hdparm -W 0 /dev/sda' が見つかればOKのはず。以下参考。
- Hardware Recommendations — Ceph Documentation - Write Caches
- https://wiki.archlinux.org/title/Hdparm
- https://wiki.archlinux.org/title/Udev#Identifying_a_disk_by_its_serial
以降はWriteCache無効の設定で測定を続けます。
2. RBD並列数による性能(n=1)
ここからは実際のユースケースに合わせて仮想マシンの数を増やしてRBDの並列アクセス性能を見ていきます。
まずはn=1のケースだけを測定します。項目は以下の通り。
- Sequential Write bs=4M iodepth=16
- Random Write bs=4K iodepth=1
- Random Write bs=4K iodepth=128
- Sequential Read bs=4M iodepth=16
- Random Read bs=4K iodepth=1
- Random Read bs=4K iodepth=128
|
|
結果
- Write
- WriteCacheの影響を確認した時と概ね同等の傾向
- Read
- Cephの利点である並列読み込みが機能して、SSD公称値よりも高いBW (MB/s)とIOPSが見られました
- Sequential ReadのBW (MB/s)は939 MB/sに到達しており、10GbE 1portの環境としては十分な性能と言えそうです
| IOPS - ave | BW (MB/s) - ave | Latency (msec) - min | Latency (msec) - max | Latency (msec) - ave | |
|---|---|---|---|---|---|
| Sequential Write bs=4M iodepth=16 | 102 | 431 | 29 | 368 | 155.7 |
| Random Write bs=4K iodepth=1 | 1270 | 5.204 | 0.559 | 14.721 | 0.78655 |
| Random Write bs=4K iodepth=128 | 31700 | 130 | 0.786 | 37.436 | 4.04285 |
| Sequential Read bs=4M iodepth=16 | 223 | 939 | 4 | 429 | 71.46 |
| Random Read bs=4K iodepth=1 | 3913 | 16 | 0.062 | 2.187 | 0.25522 |
| Random Read bs=4K iodepth=128 | 93700 | 384 | 0.046 | 14.042 | 1.36622 |
n=1のケースの結果を元に、n=2,4,8で主にWriteの性能を見ていきます。
Readはこれ以上調べてもな…と興味を失っているので測定範囲外です。
3. RBD並列数による性能(n=2,3,4)
並列数の違いでRandom Writeにどれくらい影響するかを測定していきます。
VMを必要数分作って、iniファイルは必要数分コメントアウトします。
|
|
結果
あまり冗長でも見にくいのでさっくり平均を取った結果が以下の表です。
| IOPS - ave | Latency (msec) - min | Latency (msec) - max | Latency (msec) - ave | |
|---|---|---|---|---|
| 1台 | 1270 | 0.559 | 14.721 | 0.787 |
| 2台並列(平均) | 1261 | 0.536 | 12.571 | 0.792 |
| 4台並列(平均) | 996.25 | 0.564 | 19.848 | 1.003 |
| 8台並列(平均) | 890.5 | 0.581 | 37.805 | 1.122 |
| 8台並列(平均、負荷ノード2つ) | 987.875 | 0.589 | 17.881 | 1.011 |
並列数を増やすとIOPS、Latencyが悪化していることが分かります。
測定中はceph-osdのCPU使用率が高く測定器にも影響を与えていそうだったので、8台のケースではfioの測定ノードを2つに分散させたデータも追加しています。
Latencyは露骨に影響を受けているように見えるので、実際の利用シーンではもう少し負荷は分散されてくれるだろうと思います。
ピーク性能を計画する場合は Hardware Recommendations — Ceph Documentation でも触れられているように、Cephの処理負荷に対してCPUコア当たりのIOPSを測定値と照らし合わせて判断するのが良さそうです。
Latencyのパーセンタイルで比較すると、やはり負荷ノード1台では十分な測定余裕が無いことが分かります。
| Latency (msec) | 99.00th | 99.50th | 99.90th | 99.95th | 99.99th |
|---|---|---|---|---|---|
| 負荷ノード1台 | 2.347 | 2.487 | 7.340 | 10.552 | 19.596 |
| 負荷ノード2台(平均) | 1.473 | 1.606 | 1.606 | 2.245 | 4.549 |
測定の方向性に問題が無いか SuperMicroのベンチマーク - Ceph on Supermicro BigTwin から Table 5 – 4K Random Writes の結果を拝借して見比べてみます。
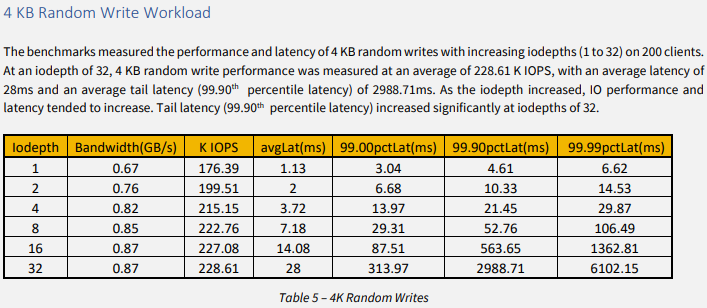
1行目の結果から、iodepth=1のクライアントが200台で176.39 KIOPSということは、200並列の場合は1クライアント当たり 881.95 IOPS。
avgLat(ms)も1.13msですから、測定結果とかなり近しい値です。
手元の環境での測定結果は8台までですが、概ね狙い通りの結果が得られたと言えそうです。
逆に、100G NICとNVMe SSD x12を揃えても、1クライアント当たりの性能傾向は手元の環境とそう大きく変わらないと思われます。
前提とするI/OワークロードによってはCeph採用に難色を示すユーザーがいる可能性はありそうですね。
4. MX500とS4500の性能差
最後に、既に利用を終了している旧クラスタ(TX1320 M2 + MX500)のCeph性能は一体どんなものだったのかを比較します。
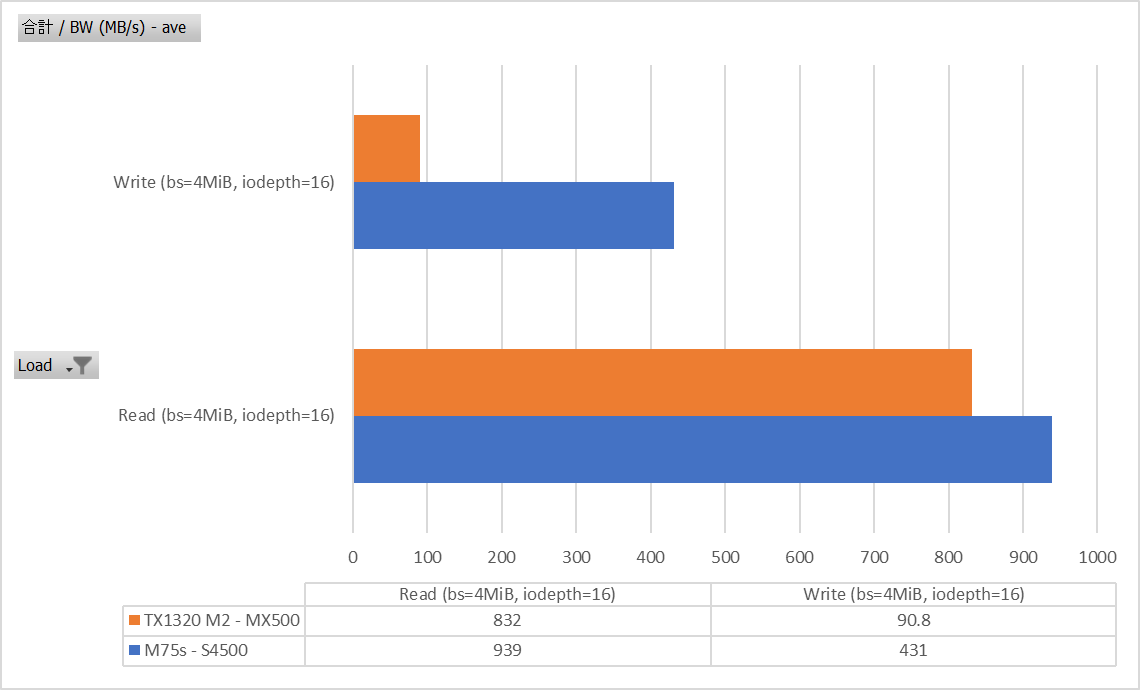
Seqeuential Read/Write bs=4M iodepth=16
Writeは1GbEの頭打ち感がありますが、Readはローカル読み出し出来るので比較的頑張っていたみたいですね。
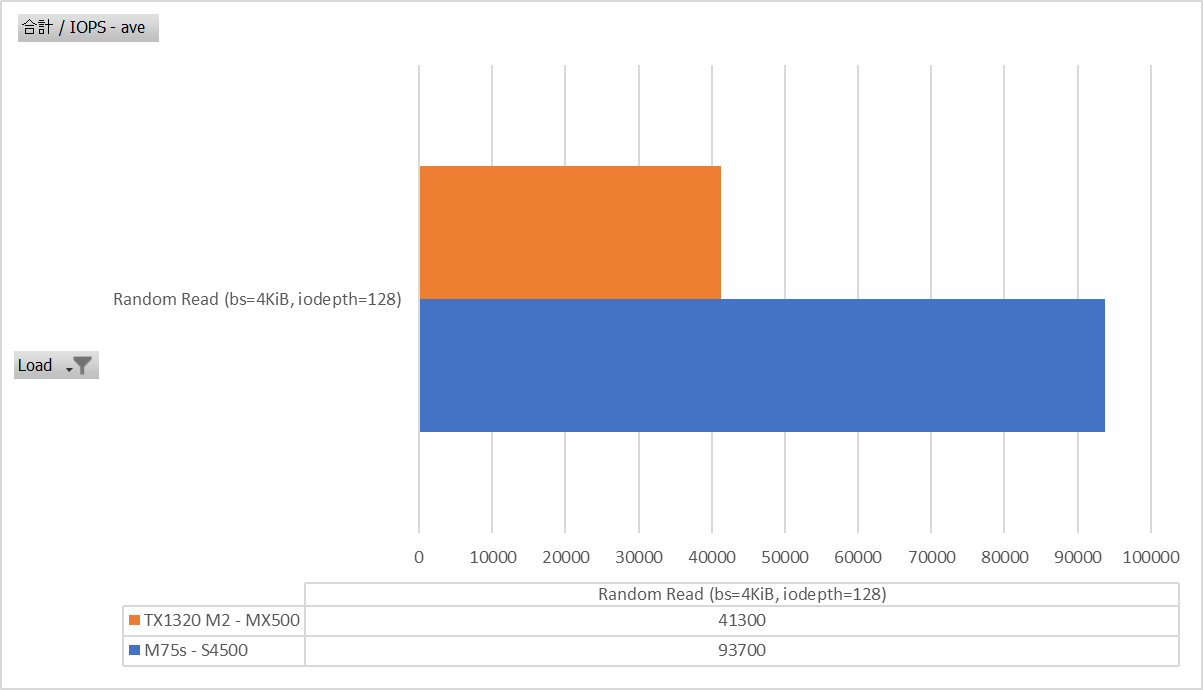
Random Read bs=4K iodepth=128
これまたReadはローカル読み出し出来るので比較的頑張っていたみたいですね。
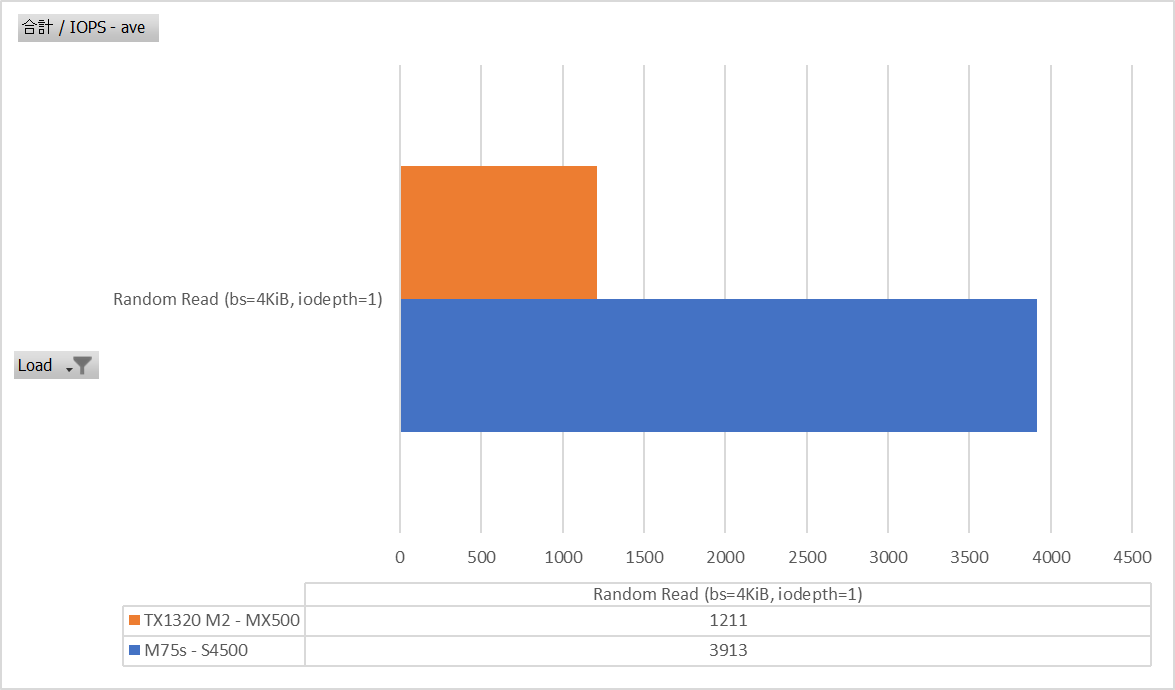
Random Read bs=4K iodepth=1
これまたReadはローカル読み出し出来るので比較的頑張っていたみたいですね。
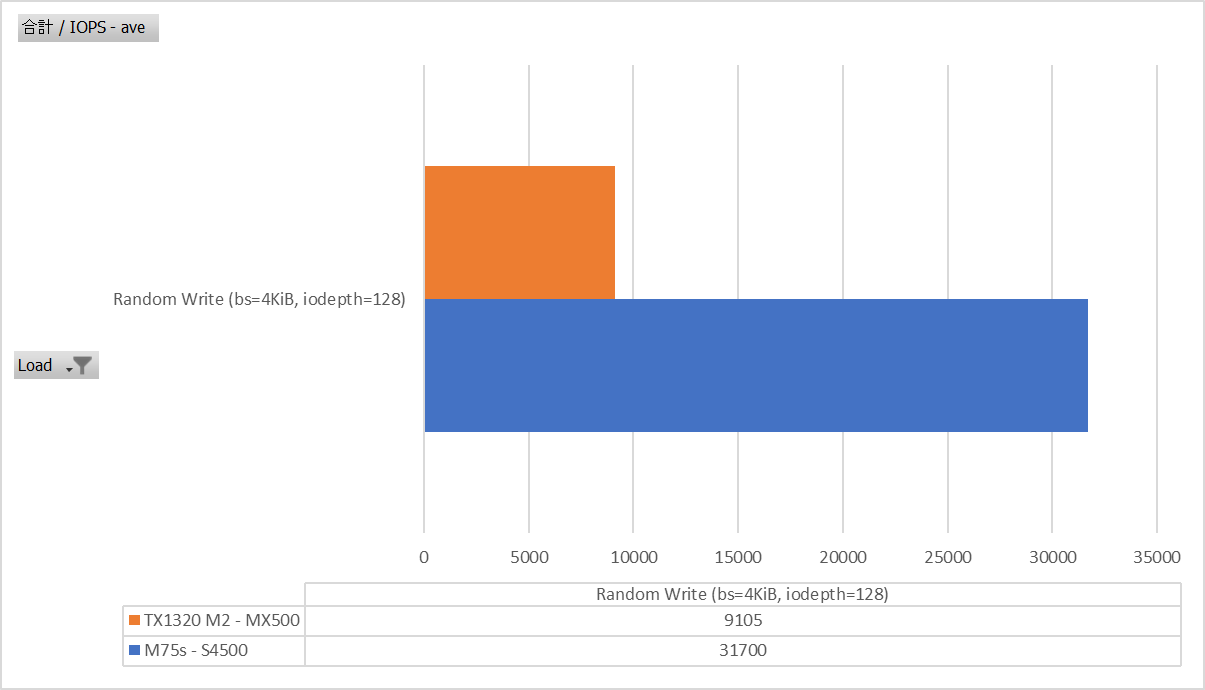
Random Write bs=4K iodepth=128
Writeはやはりどうしようもない。むしろこれでMX500がS4500と同じくらい性能出てたらどうしようかと。
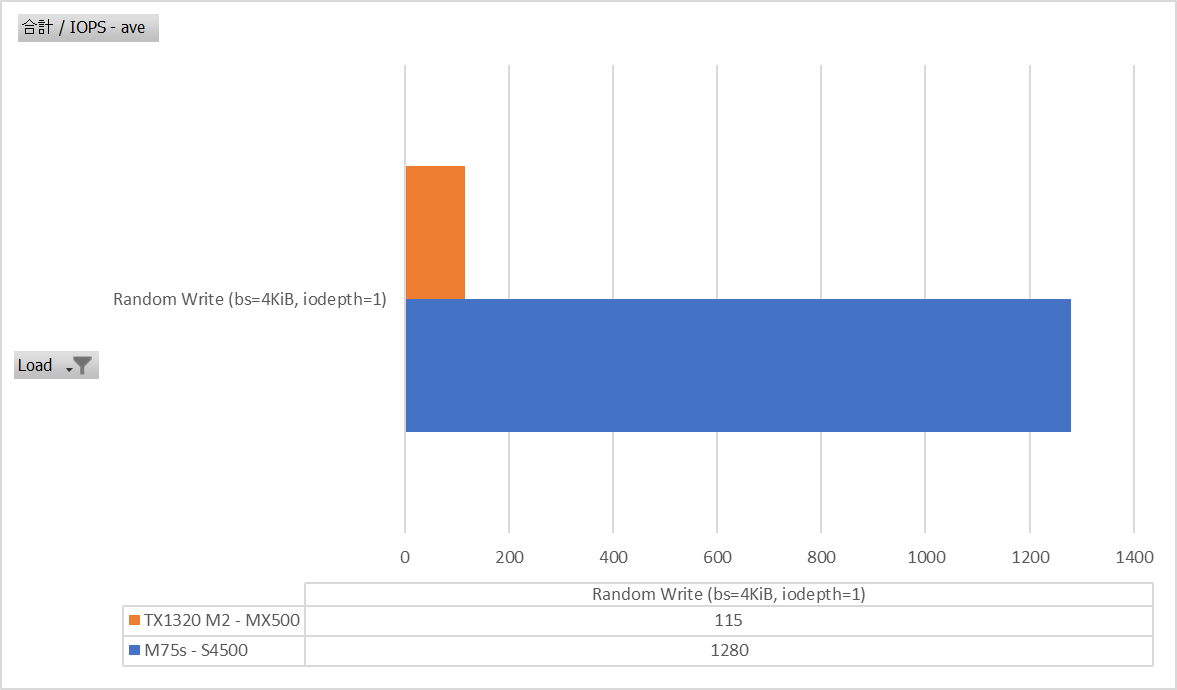
Random Write bs=4K iodepth=1
こちらはもっと露骨。
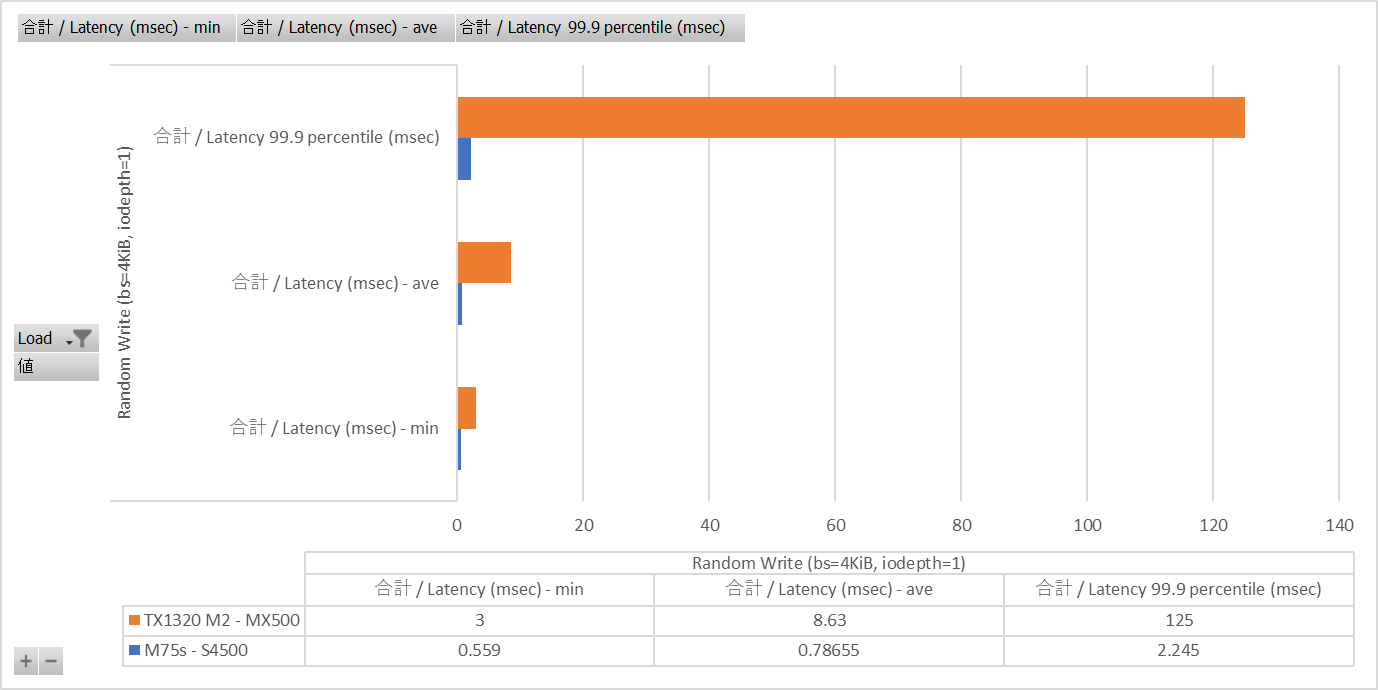
Latencyを見るとMX500の悲しい性能が際立っている。
チューニングメモ
- C6ステートを無効にしたらレイテンシが改善される可能性がありましたが、改善されたのはpingのLatency程度で特段目立った効果は無し
- SecureBoot無効にして
modprobe msrでカーネルモジュール入れてpython3 ./zenstates.py --c6-disableとかやってました
- SecureBoot無効にして
- BIOSの電源設定をPerformance modeにすると少しだけ性能改善がありそうでしたが、自宅サーバーなので見送りました
- 以下のカーネルパラメータも少しいじってみたものの、これも目立った効果は見られず
sysctl -w net.ipv4.tcp_low_latency=1sysctl -w net.ipv4.tcp_fastopen=1sysctl -w net.ipv4.tcp_timestamps=0
- cephxの認証/暗号化を無効にしてみたものの、これも目立った効果は見られず
1 2 3 4 5 6 7 8 9 10 11 12 13 14~# diff -u ceph.conf.bk /etc/ceph/ceph.conf --- ceph.conf.bk 2025-05-01 21:34:13.475309835 +0900 +++ /etc/ceph/ceph.conf 2025-05-01 21:34:35.000000000 +0900 @@ -1,7 +1,7 @@ [global] - auth_client_required = cephx - auth_cluster_required = cephx - auth_service_required = cephx + auth_client_required = none + auth_cluster_required = none + auth_service_required = none cluster_network = 172.16.0.21/24 fsid = 72fa059a-ebcd-4636-8eff-171873d5e392 mon_allow_pool_delete = true - KRBDはRandom Write 4KB iodepth=1に若干改善が見られた(1400弱くらいになる)ので、とりあえず以下の設定を採用
おしまい
データを取ったのは5月くらいで、ほとんど覚えてなかったりして。
とりあえず今はとても安定して動いています。KRBDも特に問題ないですね。
測定をやり直したりして結構書き込みしたはずなのですがWearoutがまだ0%なので、長い付き合いになるとありがたいところ。
ストレージについて | さくらのクラウド マニュアル などを見ていると全ての標準プランでは読み込みIOPS 2000、書き出しIOPS 500でした。
これくらいならCephの共用ストレージで出せそうな感じがしました。目標にするには中々いい数字です。
でもAmazon EBS 汎用 SSD ボリュームはgp3で3000 IOPSとか平然と描かれていますし、単なるCephで太刀打ちできるラインを越えてるんですよね…
これはチープな環境で戦って勝てる数字なのか、内情を知りたくなります。
一旦Cephのことは忘れて、高IOPS仮想マシンをどう払い出すかを考えるのも思索には良さそうです。
いえ、別に暇なわけでは無いですけど…
ではまた。