はじめに
Linuxでパケット単位でロードバランスする設定を例に、coreemuの宣伝をします。
今回のキーワードは、 CentOS, coreemu, iptables, fwmark, loadbalance, per-packet loadbalance 辺りでしょうか。
Install coreemu for CentOS 6.3
さっくりインストールするので、いくつか現時点のハマりどころを書いておく。
基本的には、2.2.2. Installing from Packages on Fedora/CentOS を読みながら進みましょう。
- tkimgとlibevを先にインストールしておく必要があります。(EPEL使う場合は勝手に入るのでOK)
- SELINUXを無効にするか適切に設定しないとzebra(およびルーティングデーモン)が動きません
- ホスト側でiptablesを無効にするか空っぽにしておかないと、仮想リンク間のパケットが全部叩き落とされます。
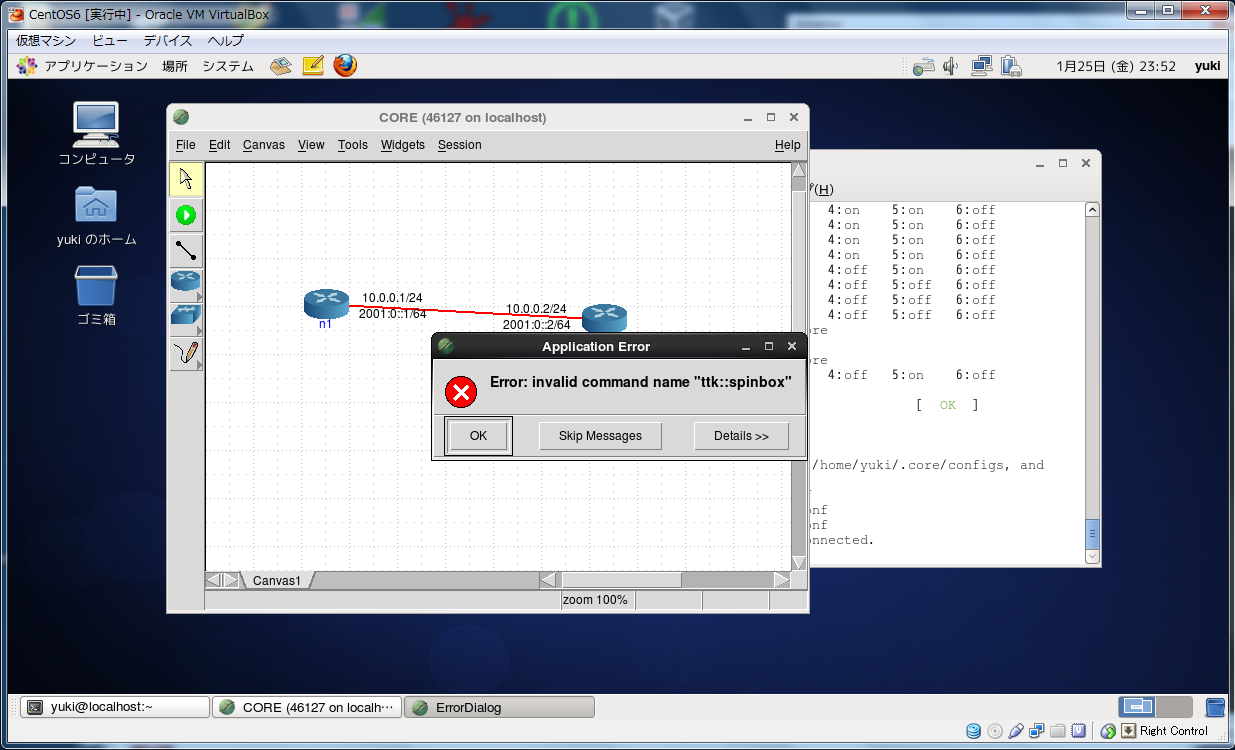
iptables -F; /etc/init.d/iptables saveとかで良いですかね。 - yumで入るtkのバージョンが古いので、仮想リンクの遅延等を設定しようとすると
Error: Invalid command name "ttk::spinbox"が出るので、tcl/tk8.5をソースからコンパイルして上書きしましょう。
また、この時tkのconfigure中にX11のライブラリリンクを要求されるのでlibX11-develをインストールしておきましょう。(以下参考画像)
Let’s topology making
さて、トポロジを作りましょう。とりあえずこんな感じですかね。(各ノードはデフォルト設定のまま放り込んでいます)
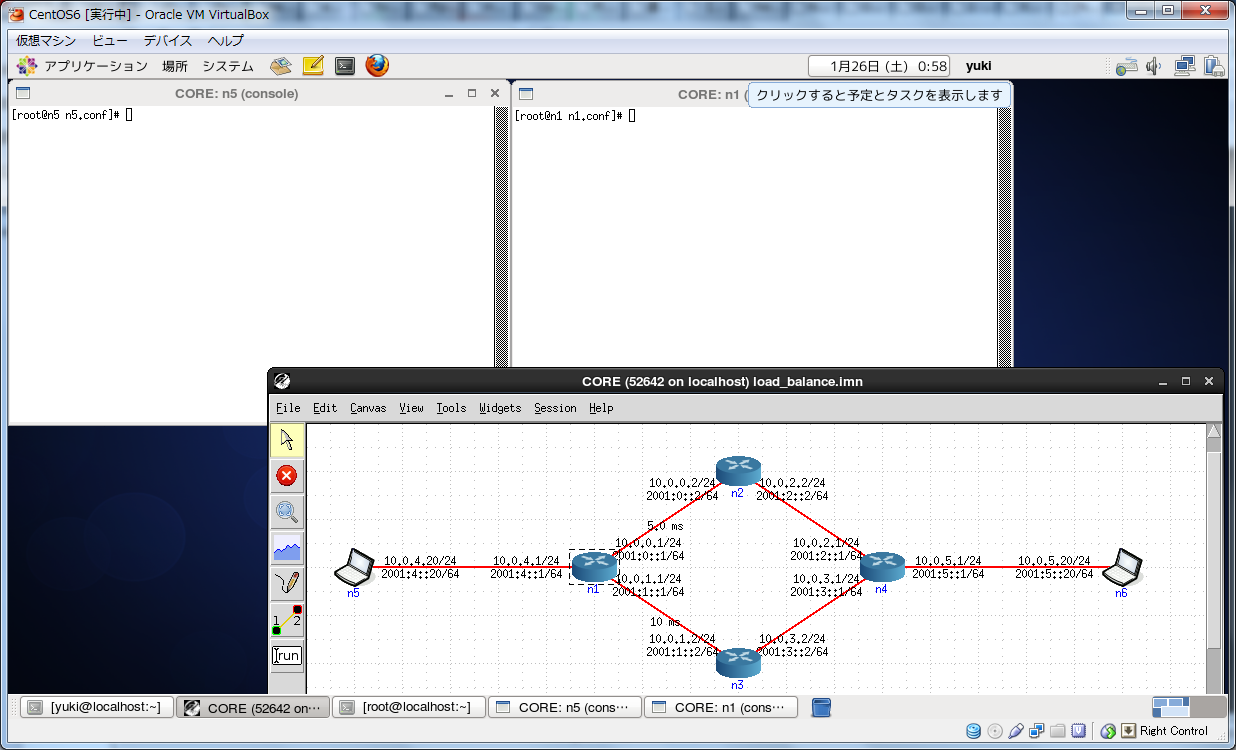
そして、OSPFのコンバージェンス後、n1のルーティングテーブルは以下のようになります。
|
|
通常時のロードバランス(ECMP)
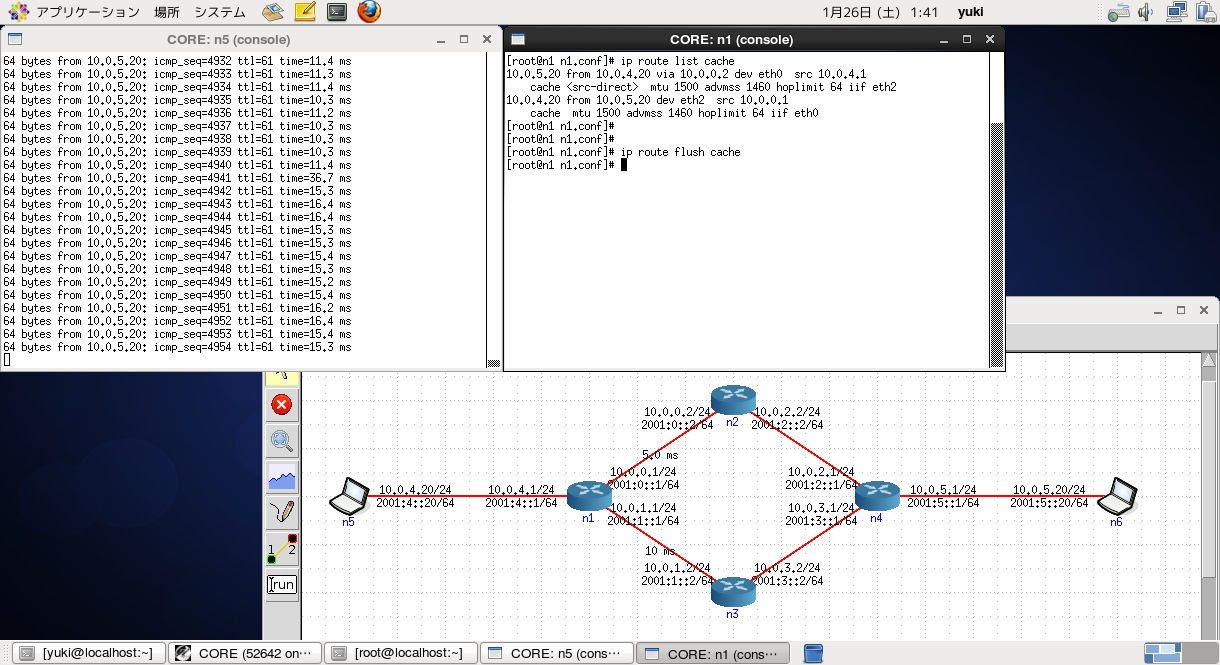
n1~n4のルータではOSPFが動作しており、特に設定をしていないので、必然的にECMP(Equal-cost multi-path)になります。
LinuxにおけるECMPの動作は、通常宛先IPベースで別々の次ホップに割り当てていくので、トラフィックが流れっぱなしになっていると、キャッシュが消えるまで常に同じ経路を通ることになります。
その動きをしているのが下の図。
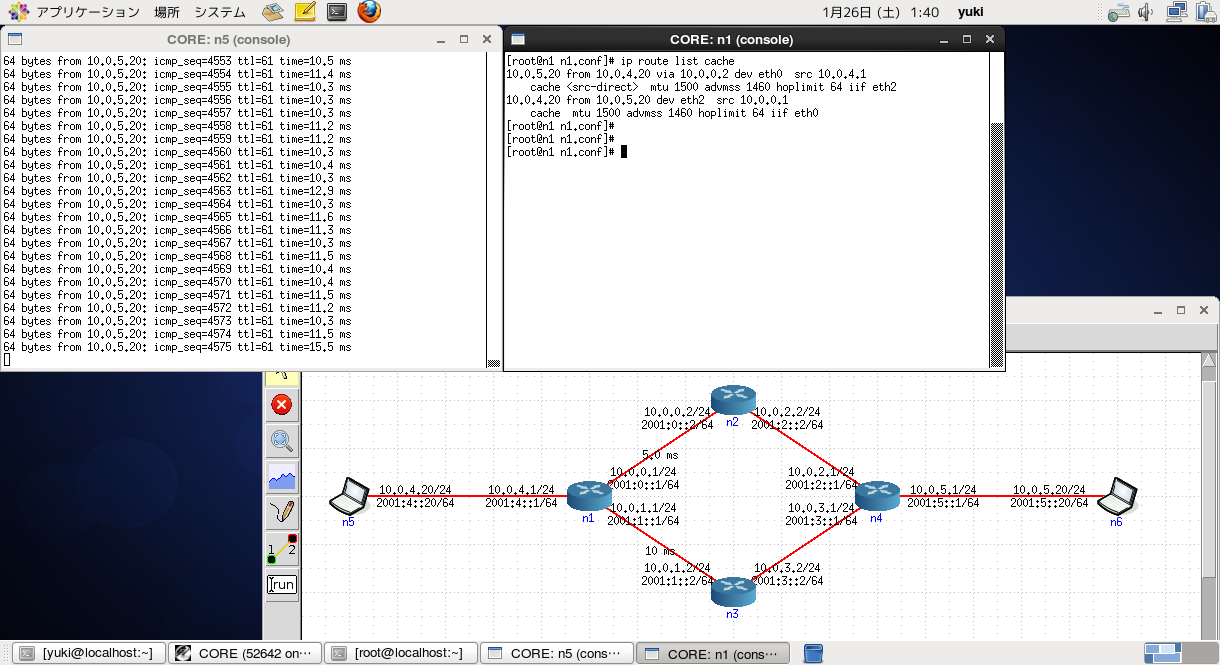
左側のノードから右側のノードに向けて ping 10.0.5.20 -i 0.1 -l 1400 のようにしてpingを投げています。
n1とn2の間は遅延5[ms]、n1とn3の間は遅延10[ms]に設定しているので、行きも帰りもn2を経由していることになります。
ここで、n1でキャッシュを確認後、消してみると、RTTが15[ms]となり、下図のように行きの経路が下を通るようになります。
OSPF等で宛先が複数あっても、パケット毎にロードバランスが行われないことは、まぁ、普通ですよね。
iptablesを用いたper-packet loadbalance
そこでiptablesを用いて、パケット毎に別々の経路を通るように設定してみます。
コンフィグはこんな感じ。
|
|
では、コンフィグ投入後の動作を見てみましょう。
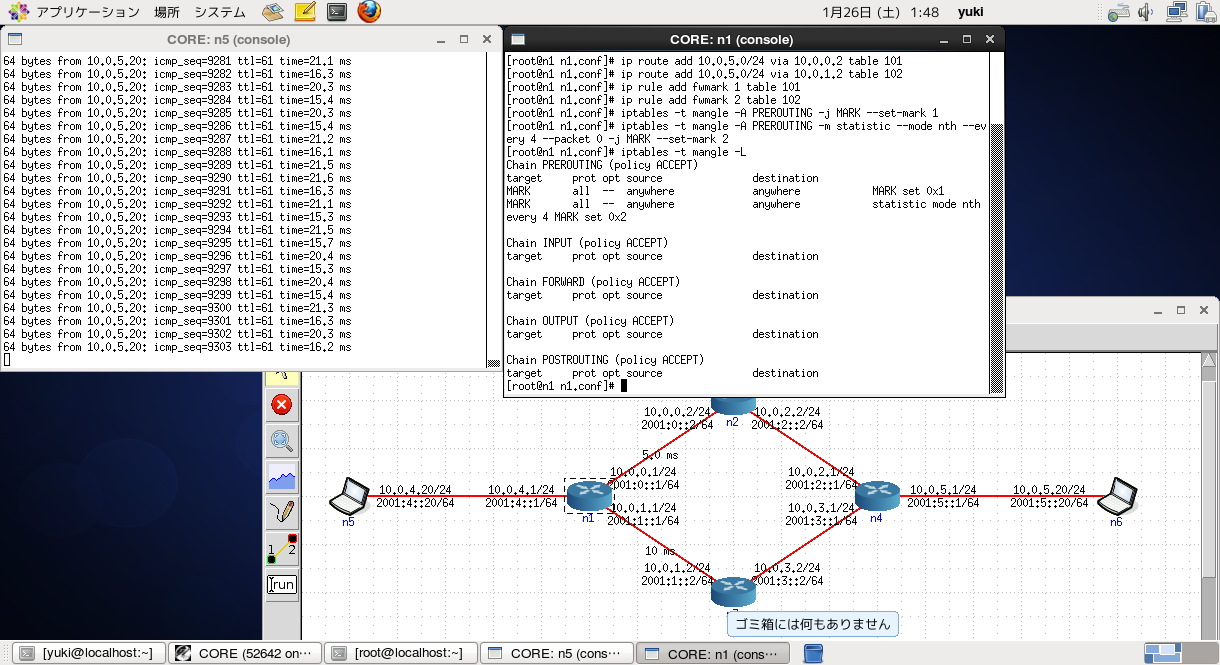
遅延が15[ms]と20[ms]で切り替わっているので、n5→n6のパケットがn1でパケット毎のロードバランスが行われていることになります。
応答パケットとなるn6→n5については、常にn3を通る経路を(n4が)選択しています。
直感からすると --every 4 は2じゃないのか、って思うんですけど、これ僕がmanを読み違えてるのか、バグなのか分かんないんですよねぇ。
ちなみに、これは確率を使うこともできるので、その場合はこうなります。
|
|
iptables -t mangle -F で一旦消して、再投入します。
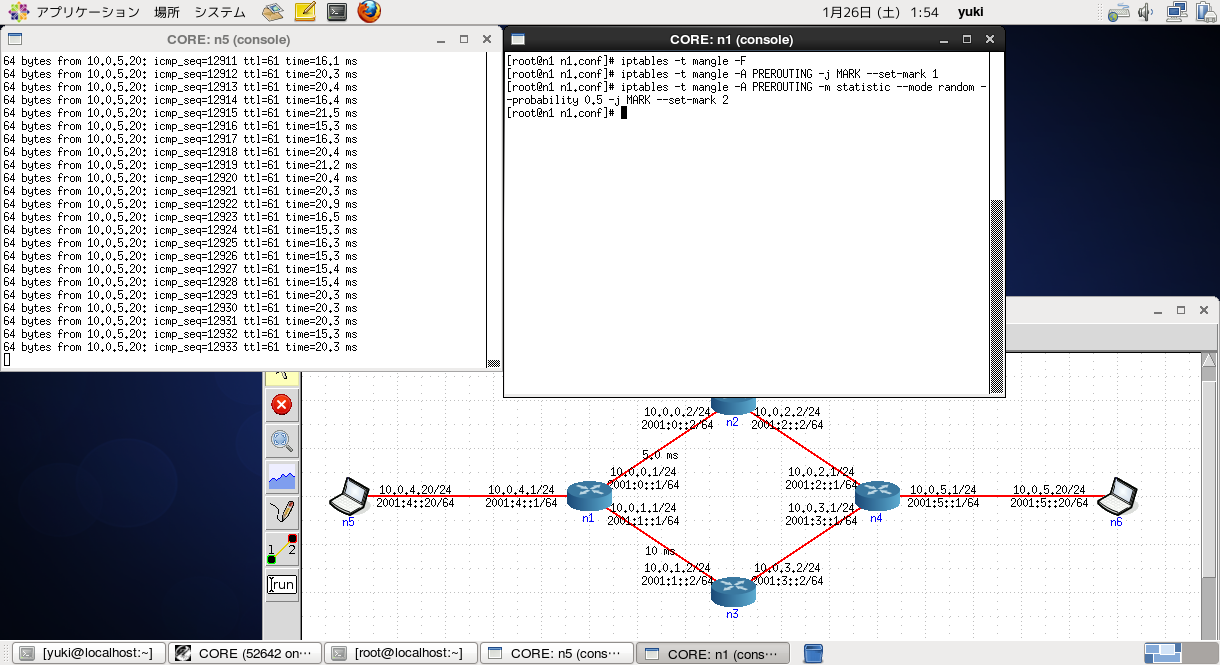
まぁ、大体50%、ということで。
終わる
というわけで、Linuxのロードバランス動作とかiptablesの設定を確認するのに、coreemuは中々使える子だよ、ってのをまた宣伝するための記事でした。
おまけ
まったくもって別件なのだけど、例えば今回のようにn5とn6でパケットキャプチャして、その間で発生したパケロスとか遅延とか、そういうネットワーク品質の測定が出来るとそれはそれで面白いだろうなぁ、と思ってるのね。
で、Pythonでちょこちょこ書いてるツールがあるんだけど、これに放り込むと良い感じに遅延が5[ms]と10[ms]になってるのが分かってちょっと自己満足してる図がこれ。
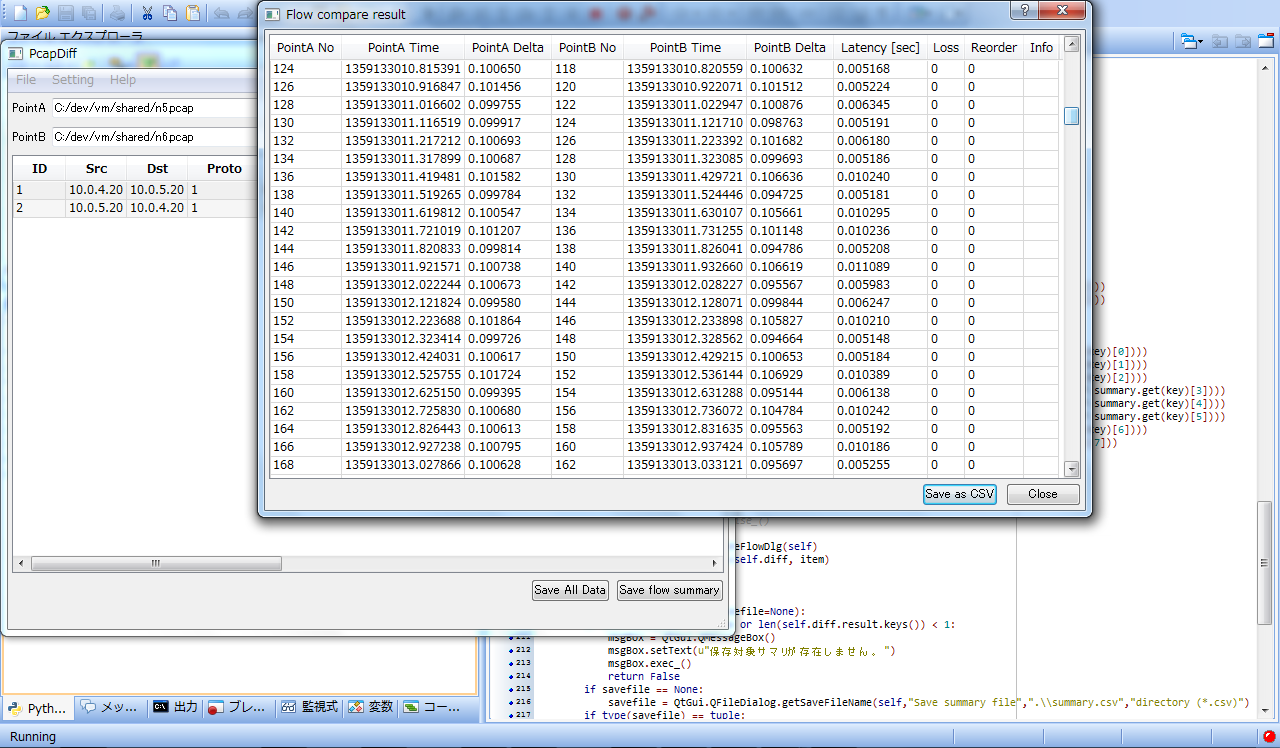
PySide可愛いよPySide。